
{kind=link}
O Espelho da Cognição
Desde os primórdios da civilização, quando os primeiros traços foram riscados na areia ou pedras foram esculpidas em formas geométricas, os jogos de tabuleiro serviram como um espelho fundamental da cognição humana. Eles não são meros passatempos; são sistemas fechados de lógica, estratégia, engano e previsão que encapsulam a complexidade da tomada de decisão humana em um ambiente controlado. É, portanto, inevitável que, na busca pela criação de uma inteligência artificial (IA) capaz de rivalizar ou superar a humana, esses mesmos tabuleiros tenham se tornado o laboratório primordial — a Drosophila melanogaster da ciência da computação.
Esta reportagem, destinada a explorar a profundidade abissal dessa interseção, não é apenas uma crônica de vitórias de máquinas sobre mestres humanos. É uma investigação sobre como o silício aprendeu a pensar através do lúdico e como, num ciclo de retroalimentação fascinante, a inteligência artificial está agora reescrevendo a história, a teoria e o futuro dos jogos que definiram nossa cultura por milênios.
Viajaremos das guarnições romanas antigas, onde algoritmos modernos ressuscitam regras esquecidas, aos supercomputadores que desvendaram a verdade matemática por trás das Damas e do Othello, até os sistemas neurais que transcendem o conhecimento humano no Go e no Xadrez.
A evolução da IA nos jogos de tabuleiro reflete a própria evolução da computação: partindo de sistemas baseados em regras rígidas e força bruta de cálculo para redes neurais intuitivas que aprendem por experiência, espelhando a plasticidade do cérebro biológico. Ao examinarmos essa trajetória, descobrimos que a IA não veio para destruir o jogo, mas para elevá-lo a uma nova dimensão de beleza e profundidade estratégica, inaugurando a era dos Centauros — a colaboração simbiótica entre a criatividade humana e a precisão algorítmica.

A Arqueologia Algorítmica Ressuscitando o Passado
A interseção entre jogos e IA é frequentemente vista sob a ótica do futurismo, mas uma das suas aplicações mais surpreendentes reside na iluminação do passado distante. A arqueologia tradicional, armada com pás e pincéis, encontra os objetos físicos; a arqueologia algorítmica, armada com simulação e aprendizado de máquina, resgata as regras imateriais que davam vida a esses objetos.
O Enigma de Ludus Coriovalli
Em fevereiro de 2026, a comunidade arqueológica e tecnológica foi abalada por uma descoberta que exemplifica o poder da IA como ferramenta historiográfica. No centro dessa descoberta estava um artefato modesto: uma laje de calcário acinzentado, medindo 21 por 14,5 centímetros, que repousava nos arquivos do Museu das Termas (agora Museu Romano) em Heerlen, nos Países Baixos, há décadas. Encontrada nas escavações da antiga cidade romana de Coriovallum, a pedra exibia incisões geométricas que sugeriam um tabuleiro de jogo, mas seu padrão não correspondia a nenhum dos passatempos romanos bem documentados, como o Latrunculi (o jogo dos mercenários) ou o Duodecim Scripta (doze linhas).
Durante anos, o objeto permaneceu um mistério silencioso. As linhas estavam lá, mas a lógica que as animava havia se perdido no tempo. Foi necessária a intervenção de uma equipe interdisciplinar liderada pelo arqueólogo Walter Crist, da Universidade de Maastricht, para quebrar esse silêncio. A abordagem da equipe não se baseou apenas na interpretação de textos clássicos, mas na aplicação pioneira de simulações de IA através do sistema Ludii, uma plataforma de software desenvolvida para modelar, jogar e analisar jogos de tabuleiro históricos.
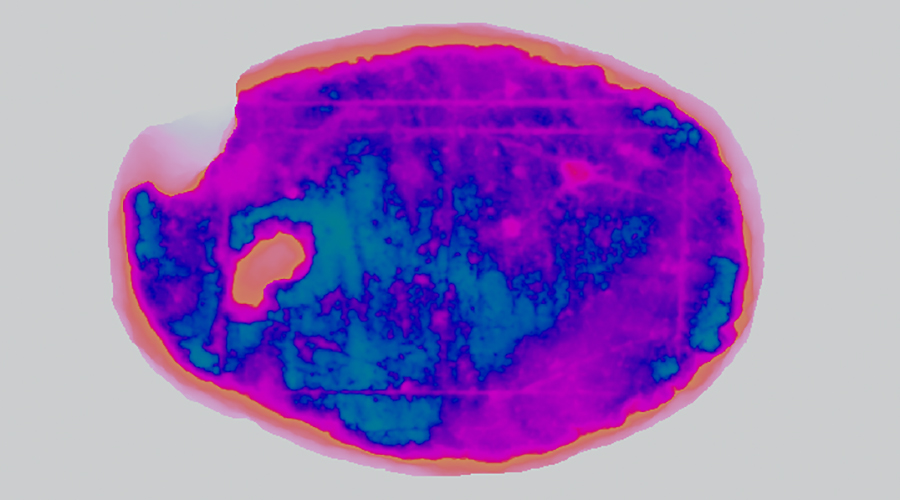
A Metodologia: Onde a Fotogrametria Encontra a Rede Neural
O processo de descoberta foi uma fusão meticulosa de ciência forense física e experimentação digital.
- Mapeamento Microtopográfico | O primeiro passo envolveu a digitalização da pedra com um nível de detalhe sem precedentes. O estúdio de restauração Restaura, em Heerlen, produziu scans 3D de alta resolução que revelaram a microtopografia da superfície da pedra. Essas imagens permitiram aos pesquisadores analisar os padrões de desgaste (use wear analysis) dentro das incisões. A hipótese central era a de que o movimento repetido de peças de jogo — fossem elas de osso, vidro ou cerâmica — ao longo de séculos deixaria marcas microscópicas de abrasão específicas, indicando rotas preferenciais, pontos de partida e áreas de alta fricção.
- Simulação Ludii | Com os dados físicos em mãos, a equipe recorreu à IA. O sistema Ludii foi programado com centenas de variações de regras plausíveis para a região e o período (séculos II a IV d.C.). Agentes de inteligência artificial jogaram milhões de partidas simuladas para cada conjunto de regras, gerando mapas de calor virtuais que representavam onde as peças digitais mais transitavam no tabuleiro simulado.
- A Convergência | O momento de revelação ocorreu quando a equipe comparou os padrões de desgaste físico da pedra real com os padrões de tráfego gerados pelas simulações. A IA identificou que apenas um tipo específico de mecânica de jogo produzia um desgaste consistente com a realidade arqueológica: um jogo de bloqueio (blocking game).
Reescrevendo a História Lúdica
A identificação do Ludus Coriovalli como um jogo de bloqueio forçou uma reescrita significativa da cronologia dos jogos de tabuleiro na Europa. Até essa análise, jogos focados puramente no bloqueio e imobilização do oponente (ao invés de captura ou corrida) eram atestados inequivocamente apenas a partir da Idade Média. A IA forneceu evidências que empurram a existência dessa mecânica entre cinco a sete séculos para trás, situando-a firmemente no período imperial romano.
As regras reconstruídas descrevem um jogo assimétrico, possivelmente um ancestral da família Haretavl (jogos de caça), onde as peças se movem ao longo de linhas diagonais e ortogonais para cercar o adversário. A análise detalhada mostrou que as linhas diagonais apresentavam um desgaste mais homogêneo e suave, consistente com o deslizamento frequente de peças duras, confirmando a natureza dinâmica e estratégica do jogo.
Esta descoberta, publicada na revista Antiquity, foi saudada como inovadora por especialistas como Véronique Dasen, da Universidade de Friburgo. Ela sugere um futuro onde a IA poderá ser usada para decifrar inúmeros outros tabuleiros mudos — grafites em fóruns romanos, riscos em pavimentos de templos egípcios ou petróglifos em cavernas — transformando marcas estáticas em sistemas vivos de interação social antiga.

A Matemática da Perfeição
Enquanto a arqueologia digital olha para trás, a ciência da computação passou as últimas décadas olhando fixamente para a frente, tentando resolver a questão fundamental proposta pelos pioneiros Charles Babbage e Claude Shannon: pode uma máquina jogar um jogo perfeitamente?
A resposta a essa pergunta levou à distinção crítica entre jogos super-humanos e jogos resolvidos. Um jogo resolvido é aquele em que o resultado final (vitória, derrota ou empate) pode ser predito com certeza matemática a partir da posição inicial, assumindo jogo perfeito de ambos os lados.
O Fim das Damas: A Saga do Chinook
O primeiro grande marco na resolução de jogos complexos de tabuleiro ocorreu no jogo de Damas (Checkers/Draughts, na variante 8×8). Esta conquista é sinônimo do nome Jonathan Schaeffer, da Universidade de Alberta, e seu programa, o Chinook.
A jornada do Chinook começou em 1989, com o objetivo de derrotar o campeão mundial humano, Marion Tinsley. Tinsley era uma lenda, tendo perdido apenas cerca de nove partidas em 45 anos. No primeiro confronto em 1992, Tinsley venceu, mas o Chinook tornou-se o primeiro programa a ganhar o direito de desafiar um campeão humano. Tinsley faleceu em 1995, e o Chinook foi declarado campeão mundial humano-máquina, mas Schaeffer não estava satisfeito. Ele queria a perfeição.
O esforço para resolver as Damas durou até 2007. O jogo possui cerca de $5 \times 10^{20}$ (500 quintilhões) de posições possíveis. Embora vasto, esse número estava no limiar do que era computacionalmente tratável.
Tabela 1: Comparativo de Complexidade de Jogos Resolvidos vs. Não Resolvidos
| Jogo | Tamanho do Tabuleiro | Complexidade do Espaço de Estados | Status da Solução | Ano da Solução/Marco |
| Jogo da Velha | 3×3 | $10^3$ | Fortemente Resolvido (Empate) | Antiguidade |
| Conect 4 | 7×6 | $4.5 \times 10^{12}$ | Fortemente Resolvido (Vitória Jogador 1) | 1988 (James D. Allen) |
| Damas (Checkers) | 8×8 | $5 \times 10^{20}$ | Fracamente Resolvido (Empate) | 2007 (Chinook) |
| Othello | 8×8 | $10^{28}$ | Fracamente Resolvido (Empate) | 2023 (Takizawa) |
| Xadrez | 8×8 | $10^{47}$ | Super-humano (Não resolvido) | 1997 (Deep Blue – marco) |
| Go | 19×19 | $10^{170}$ | Super-humano (Não resolvido) | 2016 (AlphaGo – marco) |
Para resolver as Damas, a equipe de Schaeffer utilizou uma abordagem híbrida massiva:
- Bases de Dados de Finais (Endgame Tablebases) | Eles calcularam retroativamente o resultado perfeito para qualquer posição com 10 ou menos peças no tabuleiro. Isso gerou uma base de dados de 39 trilhões de posições. Se o jogo entrasse em qualquer uma dessas configurações, o Chinook sabia o resultado instantaneamente.
- Busca Otimizada | Para posições com mais de 10 peças, o programa usava algoritmos de busca alfa-beta refinados.
Em julho de 2007, a equipe anunciou que as Damas estavam fracamente resolvidas. A prova matemática demonstrou que, se ambos os lados jogarem perfeitamente, o jogo termina invariavelmente em empate. O jogo de Damas estava, para todos os efeitos teóricos, morto — não havia mais mistério, apenas um caminho inevitável para a nulidade sob jogo perfeito.
Othello: A Conquista Recente (2023)
O desejo de resolver jogos não parou nas Damas. O jogo de Othello (ou Reversi), conhecido por sua complexidade estratégica e reviravoltas dramáticas, permaneceu um desafio aberto por décadas devido ao seu espaço de estados de $10^{28}$, significativamente maior que o das Damas.
No final de 2023, o pesquisador japonês Hiroki Takizawa, da Preferred Networks, anunciou um marco monumental: a solução fraca do Othello em um tabuleiro 8×8. Utilizando o cluster de supercomputação da empresa e uma versão modificada do software Edax, Takizawa processou bilhões de posições.
A conclusão confirmou o que muitos mestres humanos suspeitavam, mas não podiam provar: o Othello, jogado perfeitamente, é um empate. Essa conquista, detalhada em um preprint e aceita em conferências de IA, representa um dos maiores feitos de força bruta computacional e otimização de busca da década de 2020. Assim como nas Damas, saber o resultado teórico não destruiu o jogo para os humanos amadores, mas estabeleceu um padrão ouro contra o qual todas as intuições estratégicas devem ser medidas.
O Momento Sputnik do Xadrez: Deep Blue
Enquanto Damas e Othello sucumbiam à resolução matemática completa, o Xadrez permanecia o bastião cultural da inteligência. A vitória do supercomputador da IBM, Deep Blue, sobre o campeão mundial Garry Kasparov em 1997, não foi uma solução do xadrez (que permanece matematicamente não resolvido), mas foi o momento simbólico em que a máquina ultrapassou a capacidade humana em um domínio de alta complexidade.
O Deep Blue era a apoteose da Velha IA (GOFAI – Good Old-Fashioned AI). Ele não usava redes neurais ou aprendizado profundo. Em vez disso, confiava em:
- Hardware Dedicado | Chips personalizados capazes de analisar 200 milhões de posições por segundo.
- Funções de Avaliação Artesanais | Milhares de parâmetros ajustados manualmente por Grandes Mestres e programadores para ensinar ao computador conceitos como segurança do rei e controle do centro.
A vitória de Deep Blue por 3,5 a 2,5 foi um choque psicológico. Kasparov, famoso por sua preparação profunda, foi derrotado não pela criatividade, mas pela inesgotável precisão tática da máquina. Na famosa sexta partida, Kasparov cometeu um erro na abertura e desmoronou, incapaz de compreender a frieza do adversário. O Deep Blue provou que a inteligência (ou pelo menos a performance competente) poderia emergir da força bruta computacional maciça, uma lição que dominaria a IA por uma década até a chegada da revolução neural.

A Revolução Neural — A Ascensão da Intuição Artificial
Se o Deep Blue era um martelo computacional, a próxima geração de IAs seria um bisturi cognitivo. A limitação da força bruta é que ela não escala bem para jogos com fatores de ramificação extremos, como o Go, ou jogos com informação imperfeita. A solução veio da biologia: simular a intuição através de Redes Neurais Artificiais e Aprendizado por Reforço.
O Profeta Esquecido: TD-Gammon e a Mudança de Paradigma
Muitos atribuem a revolução atual à DeepMind, mas as sementes foram plantadas no início dos anos 90 por Gerald Tesauro na IBM, com seu programa TD-Gammon.
O Gamão (Backgammon) é um jogo de corrida com dados, envolvendo probabilidade e risco. A busca em árvore tradicional falhava devido à aleatoriedade dos dados. Tesauro aplicou uma técnica chamada Temporal Difference Learning (TD-Lambda), onde uma rede neural aprendia jogando contra si mesma (self-play), ajustando seus pesos com base na diferença entre suas previsões e o resultado real do jogo.
O impacto foi revolucionário e premonitório:
- Auto-Ensino | O TD-Gammon começou com conhecimento zero e atingiu o nível de mestre.
- Inovação Teórica | O programa descobriu estratégias que contradiziam séculos de sabedoria humana. O exemplo mais famoso foi a abertura com dados 2-1, 4-1 ou 5-1. A teoria humana ditava o slotting (colocar uma peça na casa 5, arriscando ser capturada para ganhar posição). O TD-Gammon preferia o “splitting” (mover uma peça do fundo, na casa 24). Inicialmente ridicularizada, a jogada da IA provou-se matematicamente superior e foi adotada pelos profissionais humanos.
O TD-Gammon foi a prova de conceito de que uma rede neural poderia desenvolver uma “intuição” posicional superior à humana, pavimentando o caminho para o que viria 20 anos depois.
O Desafio Supremo: AlphaGo e o Movimento 37
O jogo de Go, com seu tabuleiro 19×19 e pedras indistintas, oferece um número de configurações possíveis que excede o número de átomos no universo observável ($10^{170}$). A força bruta era inútil aqui. Em 2016, a maioria dos especialistas previa que uma IA capaz de vencer um profissional de Go estava a pelo menos uma década de distância.
A DeepMind, adquirida pelo Google, chocou o mundo com o AlphaGo. O sistema combinava:
- Redes de Valor e Política (Value and Policy Networks) | Redes neurais profundas que avaliavam a probabilidade de vitória de uma posição e sugeriam os movimentos mais promissores, reduzindo a largura da busca.
- Monte Carlo Tree Search (MCTS) | Um algoritmo que realizava simulações aleatórias a partir dos movimentos sugeridos para refinar a avaliação.
O momento decisivo, que entrou para a história da tecnologia, foi o Movimento 37 da segunda partida. O AlphaGo jogou uma pedra preta na quinta linha (ombro), uma jogada que nenhum mestre humano consideraria — a tradição ditava que a terceira linha é para território e a quarta para influência; a quinta era vista como ineficiente e vaga. Lee Sedol ficou tão perplexo que teve de sair da sala para se recompor. Comentaristas profissionais inicialmente classificaram o lance como um erro. No entanto, à medida que a partida se desenrolava, a genialidade daquela pedra se revelou: ela irradiava influência por todo o tabuleiro, apoiando batalhas em múltiplos frontes simultaneamente. O AlphaGo não havia apenas calculado; ele havia criado.
A Generalização Total: De AlphaZero a MuZero
A evolução acelerou. Em 2017, a DeepMind lançou o AlphaZero. Diferente do AlphaGo original, que foi treinado inicialmente com partidas humanas, o AlphaZero aprendeu tabula rasa (do zero absoluto), jogando apenas contra si mesmo. Em apenas 4 horas de treinamento, ele superou o Stockfish (o melhor motor de xadrez tradicional) e o AlphaGo.
Mas o salto final para a generalidade veio com o MuZero em 2020.
- O Problema das Regras | O AlphaZero precisava conhecer as regras do jogo (como o cavalo se move, o que é um xeque-mate). Isso limitava sua aplicação ao mundo real, onde as regras da física ou da economia são complexas ou desconhecidas.
- A Solução MuZero | O MuZero aprendeu a planejar sem conhecer as regras. Ele observa o ambiente e cria um modelo interno apenas dos aspectos relevantes para a vitória. Ele dominou Go, Xadrez, Shogi e até jogos de Atari (visuais) sem nunca ter recebido um manual de instruções.
O MuZero representa o passo mais próximo da Inteligência Artificial Geral (AGI) no contexto de jogos, demonstrando a capacidade de inferir a estrutura causal de um ambiente desconhecido apenas através da observação e recompensa.

O Renascimento Estratégico — A IA como Professora
Longe de arruinar os jogos ou torná-los obsoletos para os humanos, a ascensão da IA provocou um renascimento estratégico. Pela primeira vez na história, os humanos têm acesso a um oráculo da verdade objetiva nos jogos, o que permitiu corrigir séculos de dogmas e tradições equivocadas.
Xadrez: A Nova Beleza Dinâmica
A influência de motores neurais como o AlphaZero e o Leela Chess Zero (Lc0) transformou o xadrez de elite. Grandes Mestres (GMs) modernos, incluindo Magnus Carlsen, utilizam essas ferramentas para expandir sua compreensão.
As principais mudanças estratégicas introduzidas pela IA incluem:
- Agressividade dos Peões H | Uma marca registrada do AlphaZero foi o avanço precoce dos peões da torre (h2-h4 ou h7-h5) para criar caos a longo prazo e restringir o adversário. Antes visto como um enfraquecimento prematuro, hoje é uma manobra padrão em torneios de alto nível.
- Material vs. Atividade | As IAs demonstraram uma disposição quase imprudente para sacrificar material (peões, qualidades) em troca de atividade dinâmica das peças. O conceito de compensação a longo prazo foi redefinido; a máquina provou que a iniciativa muitas vezes vale mais do que a estrutura estática.
- Segurança do Rei Fluida | O roque não é mais automático. A IA frequentemente mantém o rei no centro se isso facilitar a coordenação das peças ou se o roque atrair um ataque direto.
Go: O Fim da Cortesia e a Eficiência Brutal
No Go, o impacto foi ainda mais profundo, derrubando a estética tradicional japonesa que valorizava a boa forma.
- A Invasão 3-3 | Historicamente, invadir o ponto 3-3 (san-san) no início do jogo era considerado tabu e estrategicamente ruim, pois dava ao oponente uma parede de influência externa muito forte. O AlphaGo provou que o território garantido (cash) no canto vale mais do que a influência nebulosa do oponente. Hoje, a invasão 3-3 é onipresente, jogada quase imediatamente na abertura.
- Desprezo pela Estética | A IA ensinou que movimentos feios (formas vazias, triângulos ineficientes) são perfeitamente aceitáveis se funcionarem taticamente. O estilo humano tornou-se mais direto, combativo e livre de preconceitos estilísticos.
Jogos de Informação Imperfeita e o Fator Humano
Enquanto Xadrez e Go são jogos de informação perfeita (nada está oculto), o mundo real — e jogos como o Poker — envolve incerteza, blefe e informação oculta.
Poker: A Arte do Engano Matemático
Em 2017, a IA Libratus, desenvolvida na Carnegie Mellon por Noam Brown e Tuomas Sandholm, derrotou quatro dos melhores profissionais de poker do mundo em No-Limit Texas Hold’em (Heads-Up). Posteriormente, o Pluribus venceu em partidas multiplayer (6 jogadores).
A vitória no poker exigiu uma abordagem radicalmente diferente:
- Minimização de Arrependimento Contrafactual (CFR) | Em vez de buscar o melhor lance em uma árvore de possibilidades fixa, a IA joga trilhões de mãos contra si mesma e pergunta: “Quanto eu teria ganho a mais se tivesse agido diferente?“. Ela ajusta sua estratégia para minimizar esse arrependimento futuro.
- Equilíbrio de Nash e Blefe | O Libratus não blefa por emoção. Ele blefa para manter suas frequências de aposta matematicamente equilibradas, tornando impossível para o oponente ler sua mão. Ele ensinou aos humanos a importância do bet sizing (tamanho da aposta) variado e a construção de ranges perfeitamente balanceados.
O Modelo Centauro: A Colaboração Humano-Máquina
A narrativa de Máquina vs. Humano é midiática, mas a realidade prática é a do Centauro. Conceituado por Garry Kasparov após sua derrota, o Xadrez Centauro (Advanced Chess) permite que humanos joguem assistidos por computadores.
A descoberta fundamental desses torneios foi que:
$$Humano (Fraco) + M\acute{a}quina + Melhor Processo > M\acute{a}quina (Forte) > Humano (Forte)$$
Um humano mediano, que sabe como usar a máquina (guiando a busca estratégica enquanto a máquina verifica a tática), pode superar uma IA superpotente jogando sozinha.
O Caso Russo de 2021 (Go) | Uma validação recente desse modelo ocorreu no Go. Em 2021, dois dos jogadores mais fortes da Rússia adotaram a estratégia de centauro digital para enfrentar a IA Leela Zero (um clone open-source forte do AlphaZero). Operando em conjunto com a IA — usando-a para verificar leituras mas mantendo a decisão estratégica humana — a dupla humana emergiu vitoriosa. Este evento demonstrou que, mesmo em domínios onde a IA é super-humana, a intuição humana ainda possui valor quando usada para direcionar e contextualizar o poder de cálculo bruto.
Horizontes Futuros e Impacto Social
A odisseia da IA através dos jogos está longe de terminar; na verdade, ela está apenas transbordando para o mundo real. As tecnologias desenvolvidas para dominar o Go e o Xadrez estão sendo reaplicadas para resolver problemas de complexidade comparável na ciência e indústria.
Do Tabuleiro para o Espaço e a Biologia
- NASA e MuZero | A tecnologia do MuZero está sendo investigada pela NASA para sistemas de despacho de elevadores e planejamento de missões autônomas, onde a regra do ambiente (o espaço desconhecido ou falhas mecânicas imprevistas) não pode ser totalmente programada a priori. O algoritmo aprende a otimizar rotas e recursos da mesma forma que aprendeu a otimizar território no Go.
- AlphaFold | Derivado diretamente das arquiteturas do AlphaGo, o AlphaFold resolveu o problema do dobramento de proteínas, um desafio biológico de 50 anos, prevendo a estrutura 3D de quase todas as proteínas conhecidas pela ciência. O tabuleiro aqui era a geometria molecular, e a pontuação era a estabilidade energética.
- Design de Jogos | A IA está começando a ser usada para criar e equilibrar jogos. Ferramentas como o Ludii não servem apenas para arqueologia, mas para testar se um novo jogo de tabuleiro moderno é equilibrado ou quebrado antes mesmo de ser lançado ao mercado.
A Inteligência como Processo
A jornada da IA através dos jogos de tabuleiro nos ensinou uma lição de humildade e esperança. A humildade vem de reconhecer que a intuição humana, que valorizávamos como mágica, é muitas vezes repleta de preconceitos e ineficiências que o silício pode expor. A esperança vem da constatação de que, ao remover esses véus, a IA nos permite ver a verdadeira beleza e profundidade dos jogos que criamos.
O futuro não é de substituição, mas de amplificação. Seja descobrindo as regras perdidas de um jogo romano de 1.800 anos ou navegando pelas incertezas de uma missão espacial, a mente humana e a mente de silício provaram ser parceiras indispensáveis. O tabuleiro eterno continua, e agora, temos um novo jogador à mesa — um que, ao nos vencer, nos ensina a jogar melhor o jogo da nossa própria existência.